from sklearn.feature_extraction import DictVectorizer import csv from sklearn import tree from sklearn import preprocessing from sklearn.externals.six import StringIO
# Read in the csv file and put features into list of dict and list of class label allElectronicsData = open(r'/home/zhoumiao/MachineLearning/01decisiontree/AllElectronics.csv', 'rb') reader = csv.reader(allElectronicsData) headers = reader.next()
print(headers)
featureList = [] labelList = []
for row in reader: labelList.append(row[len(row)-1]) rowDict = {} for i inrange(1, len(row)-1): rowDict[headers[i]] = row[i] featureList.append(rowDict)
print(featureList)
# Vetorize features vec = DictVectorizer() dummyX = vec.fit_transform(featureList) .toarray()
# Using decision tree for classification # clf = tree.DecisionTreeClassifier() clf = tree.DecisionTreeClassifier(criterion='entropy') clf = clf.fit(dummyX, dummyY) print("clf: " + str(clf))
# Visualize model withopen("allElectronicInformationGainOri.dot", 'w') as f: f = tree.export_graphviz(clf, feature_names=vec.get_feature_names(), out_file=f)
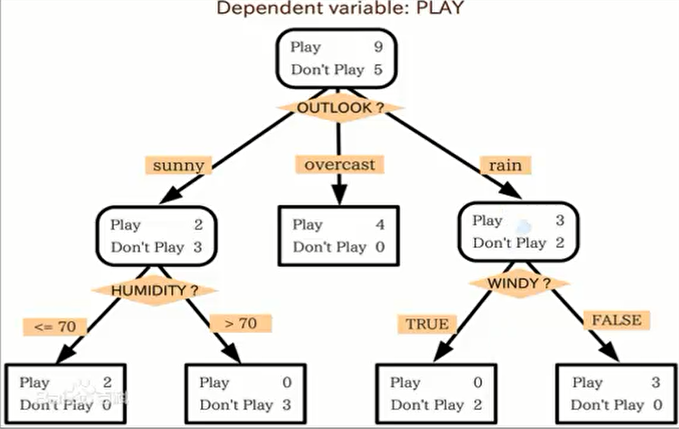
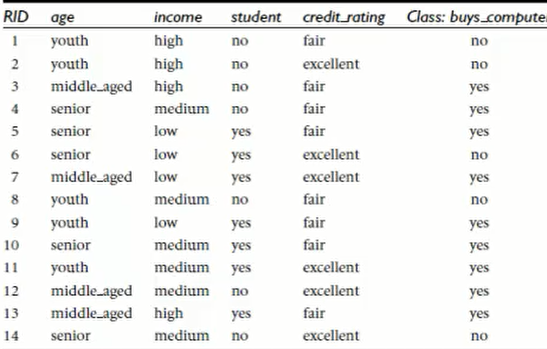 我们以此图为例来讲解求解过程。首先最后一行是我们想要知道的答案
我们以此图为例来讲解求解过程。首先最后一行是我们想要知道的答案

 这是上例所形成的列表
这是上例所形成的列表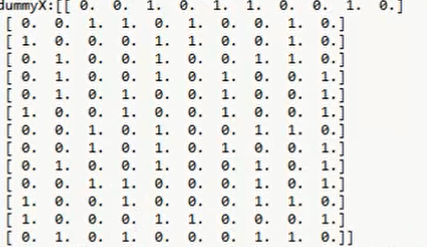
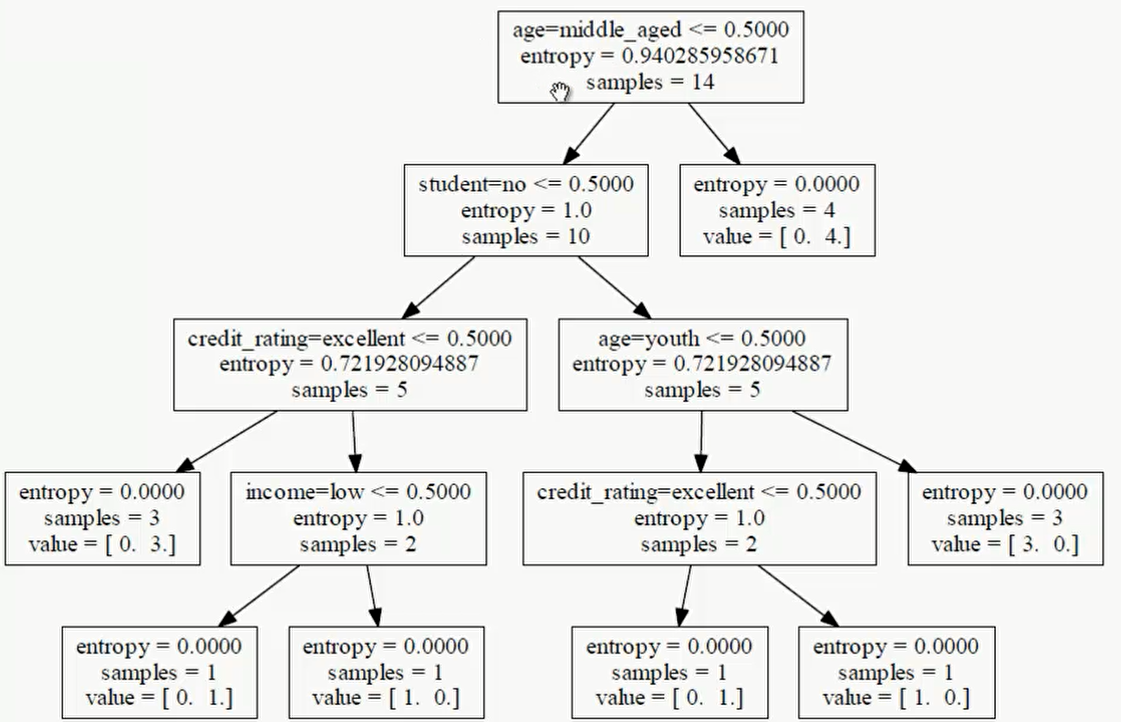
 可以看到结果非常不直观,因此我们还需用graphviz进一步转化。
可以看到结果非常不直观,因此我们还需用graphviz进一步转化。